

Authors:
(1) Suriya Gunasekar, Microsoft Research;
(2) Yi Zhang, Microsoft Research;
(3) Jyoti Aneja, Microsoft Research;
(4) Caio C´esar Teodoro Mendes, Microsoft Research;
(5) Allie Del Giorno, Microsoft Research;
(6) Sivakanth Gopi, Microsoft Research;
(7) Mojan Javaheripi, Microsoft Research;
(8) Piero Kauffmann, Microsoft Research;
(9) Gustavo de Rosa, Microsoft Research;
(10) Olli Saarikivi, Microsoft Research;
(11) Adil Salim, Microsoft Research;
(12) Shital Shah, Microsoft Research;
(13) Harkirat Singh Behl, Microsoft Research;
(14) Xin Wang, Microsoft Research;
(15) S´ebastien Bubeck, Microsoft Research;
(16) Ronen Eldan, Microsoft Research;
(17) Adam Tauman Kalai, Microsoft Research;
(18) Yin Tat Lee, Microsoft Research;
(19) Yuanzhi Li, Microsoft Research.
Table of Links
- Abstract and 1. Introduction
- 2 Training details and the importance of high-quality data
- 2.1 Filtering of existing code datasets using a transformer-based classifier
- 2.2 Creation of synthetic textbook-quality datasets
- 2.3 Model architecture and training
- 3 Spikes of model capability after finetuning on CodeExercises, 3.1 Finetuning improves the model’s understanding, and 3.2 Finetuning improves the model’s ability to use external libraries
- 4 Evaluation on unconventional problems with LLM grading
- 5 Data pruning for unbiased performance evaluation
- 5.1 N-gram overlap and 5.2 Embedding and syntax-based similarity analysis
- 6 Conclusion and References
- A Additional examples for Section 3
- B Limitation of phi-1
- C Examples for Section 5
B Limitation of phi-1
While finetuning through simple exercises significantly enhances the model’s overall performance, there are certain constraints intrinsic to our model that cannot be overcome solely by finetuning. Firstly, our model has only 1.3B parameters trained with only 7B tokens, this restricts our model’s capacity to manage more complex tasks such as developing an intricate Flask application, in comparison to other models like Starcoder. Beyond our model’s limitations in terms of generality when contrasted with StarCoder or ChatGPT, we’ve also outlined several other weaknesses as follows:
Sensitivity to prompt variations. Our model is sensitive to various perturbations of prompts. First, its performance drops significantly as the length of the prompt increases, as it tends to ignore, forget or misinterpret parts of the prompt when it is too long. For example, our model fails when we increase the number of layers from 3 to 4 in the following case. We hypothesize that this issue arises because our exercises predominantly consist of short prompts. Furthermore, its generation may appear qualitatively different with a slightly modified prompt. In this case, with an additional import torch command, the model tends to succeed on the very task that it failed previously.

Sensitivity to natural language inputs. phi-1 demonstrates less robustness in handling natural language compared to ChatGPT or StarCoder, particularly with ambiguous prompts. This may be because we filter out certain types of data from the training process to guarantee textbook-level quality. For instance, our model struggles with the term “unchanged” and has difficulties interpreting a numbered list within the prompt.

Bad at counting and spatial reasoning. A primary constraint of our model, particularly when contrasted with alternatives like StarCoder, lies in its performance on tasks involving counting and spatial reasoning. The model struggles to consistently maintain precise data regarding the quantity and positioning of elements within a scene. To illustrate, consider the following example:
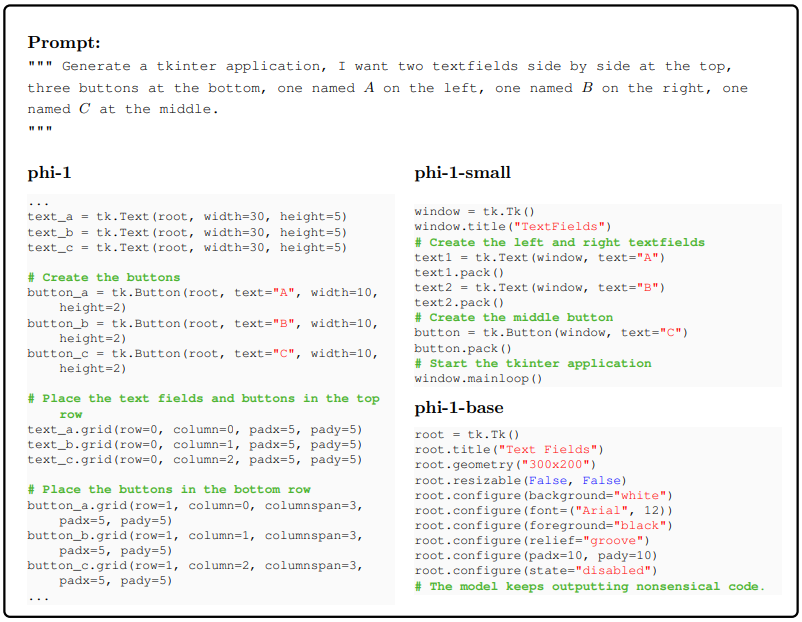
Despite the improvement from finetuning, our model still struggles with counting and spatial reasoning. It generates an extra textfield and misplaces the button in the scene.
This paper is available on arxiv under CC BY 4.0 DEED license.