

Authors:
(1) Keivan Alizadeh;
(2) Iman Mirzadeh, Major Contribution;
(3) Dmitry Belenko, Major Contribution;
(4) S. Karen Khatamifard;
(5) Minsik Cho;
(6) Carlo C Del Mundo;
(7) Mohammad Rastegari;
(8) Mehrdad Farajtabar.
Table of Links
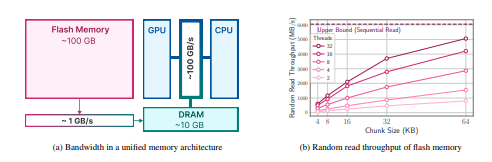
2. Flash Memory & LLM Inference and 2.1 Bandwidth and Energy Constraints
3.2 Improving Transfer Throughput with Increased Chunk Sizes
3.3 Optimized Data Management in DRAM
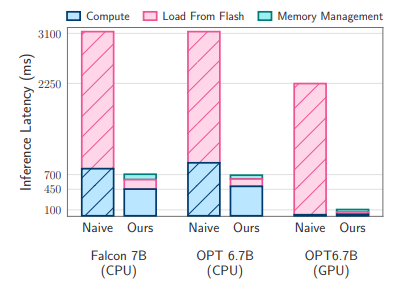
4.1 Results for OPT 6.7B Model
4.2 Results for Falcon 7B Model
6 Conclusion and Discussion, Acknowledgements and References
Abstract
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their substantial computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this hardware-informed framework, we introduce two principal techniques. First, “windowing” strategically reduces data transfer by reusing previously activated neurons, and second, “row-column bundling”, tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory
1 Introduction
In recent years, large language models (LLMs), such as GPT-3 (Brown et al., 2020), OPT (Zhang et al., 2022b), and PaLM (Chowdhery et al., 2022), have demonstrated strong performance across a wide range of natural language tasks. However, the
unprecedented capabilities of these models come with substantial computational and memory requirements for inference. LLMs can contain hundreds of billions or even trillions of parameters, which makes them challenging to load and run efficiently, especially on resource-constrained devices.
Currently, the standard approach is to load the entire model into DRAM (Dynamic Random Access Memory) for inference (Rajbhandari et al., 2021; Aminabadi et al., 2022). However, this severely limits the maximum model size that can be run. For example, a 7 billion parameter model requires over 14GB of memory just to load the parameters in half-precision floating point format, exceeding the capabilities of most edge devices.
To address this limitation, we propose to store the model parameters in flash memory, which is at least an order of magnitude larger than DRAM. Then, during inference, we directly load the required subset of parameters from the flash memory, avoiding the need to fit the entire model in DRAM. Our method is built on the top of recent works that have shown LLMs exhibit a high degree of sparsity in the Feed Forward Network (FFN) layers, with models like OPT (Zhang et al., 2022b), Falcon (Almazrouei et al., 2023), and Persimmon (Elsen et al., 2023), exhibiting more than 90% sparsity (Mirzadeh et al., 2023; Liu et al., 2023b). We exploit this sparsity to selectively load only parameters from flash memory that either have non-zero input or are predicted to have nonzero output. Specifically, we discuss a hardwareinspired cost model that includes flash memory, DRAM, and compute (CPU or GPU). Then, we introduce two complementary techniques to minimize data transfer and maximize flash memory throughput:
• Windowing: We load and temporarily cache parameters for only the past few tokens, reusing aggregate sparsity structure predicted over the past few tokens. This sliding window approach reduces the number of IO requests to load weights.
• Row-column bundling: We store a concatenated row and column of the up-projection and down-projection layers to read bigger contiguous chunks from flash memory. This increases throughput by reading larger chunks.
To further minimize the number of weights to be transferred from flash memory to DRAM, we also employ methods to predict FFN sparsity and avoid loading zeroed-out parameters, akin to approaches documented in Deja Vu (Li and Lu, 2023). Together, windowing and sparsity prediction allow us to load only 2% of the FFN layer from flash for each inference query. We also propose a static memory preallocation to minimize transfers within DRAM and reduce inference latency. Our load from flash cost model captures the tradeoff between loading less data and reading bigger chunks. Optimizing this cost model and selectively loading parameters on demand yields flash loading strategies that can run models 2x larger than the device’s DRAM capacity and speed up inference by 4-5x and 20-25x compared to naive implementation in CPU and GPU, respectively. It significantly outperforms the baseline approach, which reloads the model’s weights on every forward pass.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.